In 2018, a new type of low discrepancy quasirandom sequences based on the golden ratio has been presented by Dr. Martin Roberts, commonly called “Roberts Sequences” or in the 2D case, R2 sequence.
Quasirandom sequences are ubiquitous in rendering, as they provide not-quite-random numbers that produce more even distributions than purely random numbers. This makes them useful for a host of applications such as ray tracing, monte carlo simulations and temporal anti aliasing. The linked blog post by Dr. Roberts contains a good primer on the topic.
The Roberts sequence(s) have become very popular because of their simplicity and effectiveness, as they perform on par with existing state of the art (Sobol sequence) but are much easier to compute, a single line of code. They are the provably optimal type of so-called Weyl sequences, which follow the same structure but use any number as parameter, not necessarily the golden ratio.
So… can we improve something provably optimal?
Math vs Computers
The Roberts Sequence are versions of the so-called Weyl sequence, with parameters derived from the golden ratio. In fact, they are the Weyl sequences with provably lowest discrepancy (well-distributedness). So, how can we improve something provably optimal? And wait, are there actually problems with it?
One downside of the Roberts Sequences is that they use floating point math. Like any other quasirandom sequence, they take an index and convert it to a tuple of values between 0 and 1. Other sequences like Sobol or van der Corput operate purely on integers first and convert to floating point at the very end, which results in no float precision loss for higher indices.
The Roberts Sequences however suffer from decreasing float precision for higher indices:
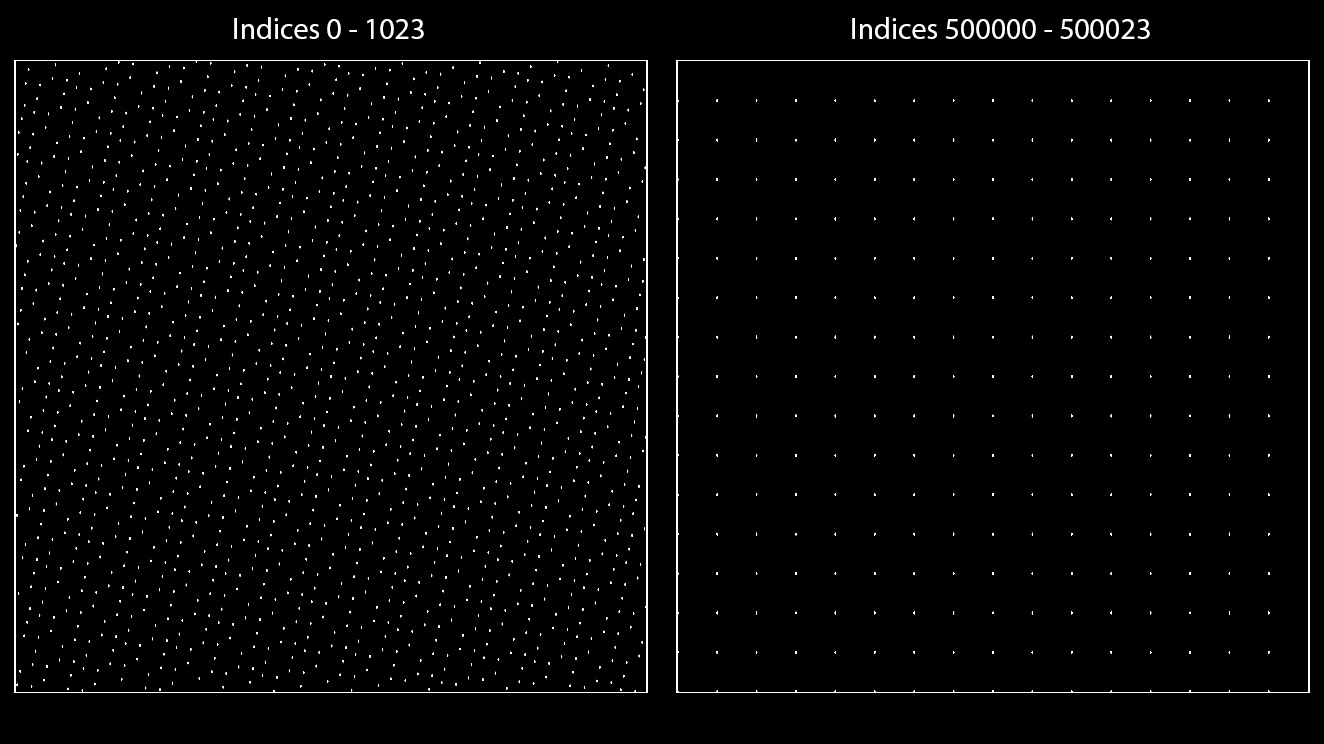
As you can see, generating the first 2^10 indices produces a very even coverage of the domain. High indices however become quantized, as in these ranges, 32 bit floats can evidently only represent 16 distinct numbers between one integer to the next. It gets worse with higher indices until the sequence only outputs (0, 0).We expect to receive unique numbers (quasi random sequences never repeat, and never output any of the previous numbers) but all we get is something quantized to 1/16, 1/8, 1/4 and so on.
So, what can we do about this? The issue is obviously worse, the higher the numbers become.
What if we could replace the generalized golden ratio with smaller coefficients so the resulting index * coefficient grows slower, dropping below a certain precision threshold at a much higher index?
But the existing coefficients are the provably optimal ones! We can’t switch them out for something else without getting an inferior sequence.
Well actually… we can.
Reformulating the sequence
The basic gist is to add the index a second time into the function before the modulo 1 (as the fractional part of any number stays same if you add an integer on top), which allows us to restructure the equation in a way that instead of using Roberts’ original α, we use 1-α instead, which is a smaller number.
We can even omit the 1 minus in front of the resulting equation, as this is just flipping the numbers, which has no adverse effects. We can do this with the higher order golden ratio based cofficients as well, and as they grow closer to 1 for higher dimensions, their counterparts becomes increasingly smaller. In other words, this method becomes even more efficient, the higher the dimension. For 3D, the coefficients are (0.8191725133961, 0.6710436067038, 0.5497004779019) and their new counterparts are (0.180827486604, 0.328956393296, 0.450299522098).
That seemed awfully simple, does this actually work?
VERIFYING THE SOLUTION
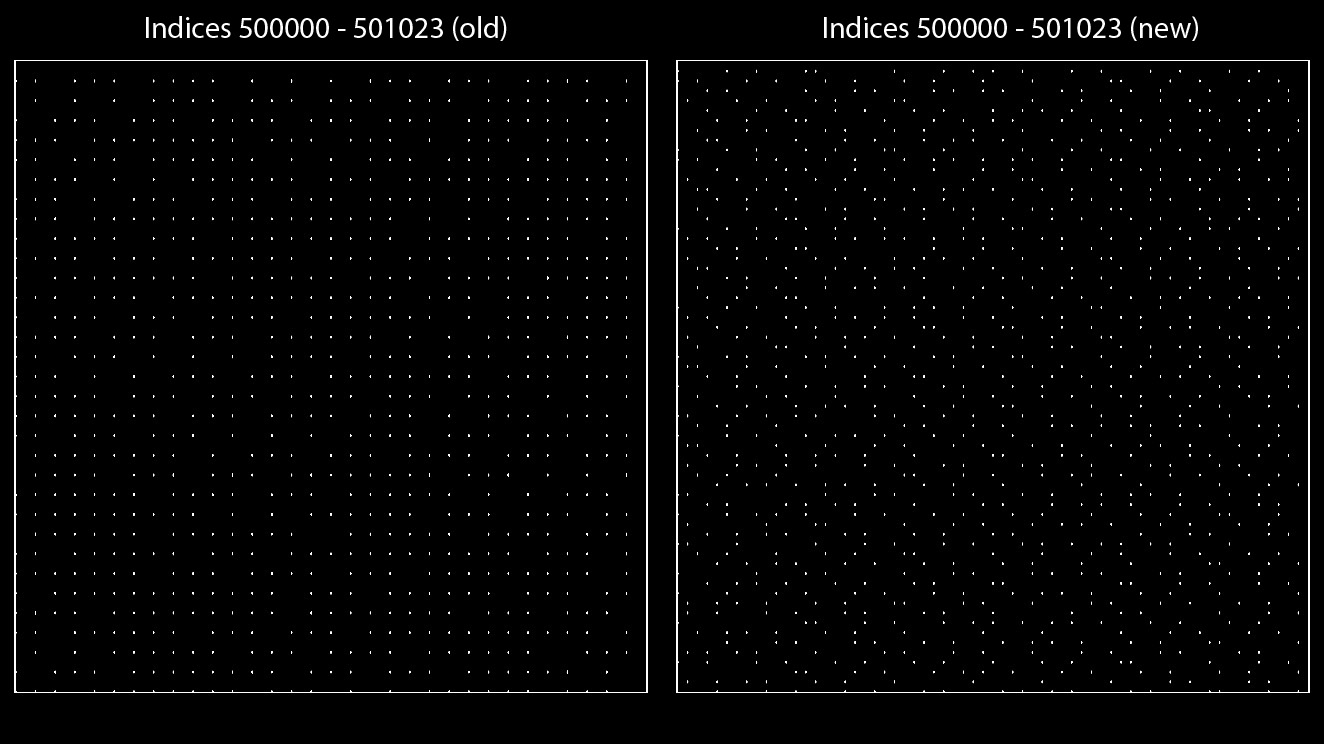
Success! The indices are far less quantized at similar ranges. In fact, with our new coefficients, we can generate over 1.1 million offsets before the quantization reaches the level of the original function. And the new sequence looks identical (albeit flipped) to the original sequence:
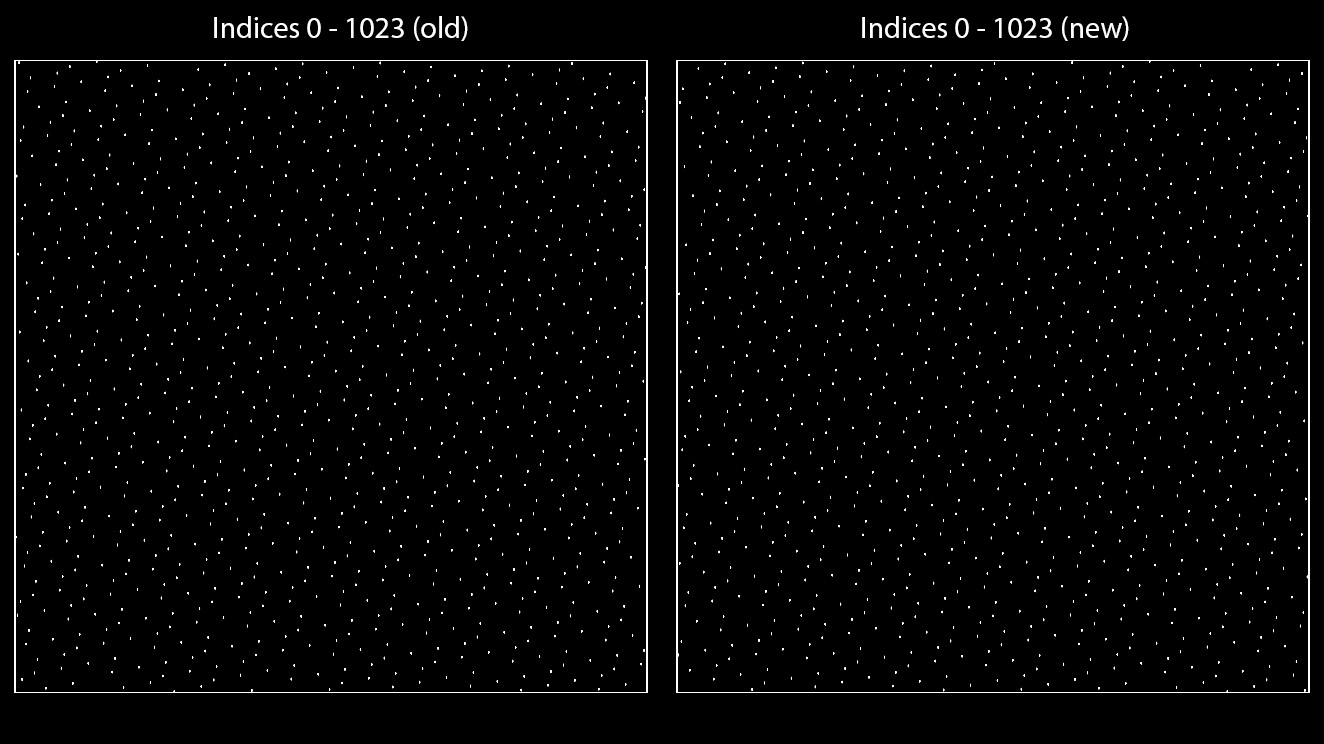
The improved sequences produce the same numbers but show >2x the amount of precision at any given time. When implementing this, it is up to the user whether they want the same numbers or keep the same performance, as omitting the 1- in front of the equation results in the exactly same instructions, but naturally flips the pattern.
Over the entire domain, the improved precision also shows in better overall coverage:

But wait! You said that the original values for the Roberts Sequences are optimal… does that mean that somehow, this new method is ever so slightly inferior? I want the best!
I originally found this method purely by accident by noticing that the related Vogel spiral uses the smaller coefficient as rotation angle and I wondered how that was possible, and investigated the mathematical foundations later. Re-reading Dr. Roberts’ blog post, he mentions that there are an infinite number of other values of α that also give the lowest possible discrepancy but they are all related via the Moebius transformation.
As shown, it is possible to write 1 minus α using valid coefficients for the Moebius transform, hence the new coefficients also provably show optimal discrepancy. They are therefore a valid replacement for the existing coefficients used in various shadertoys, game engines and other code bases, exhibiting superior numerical precision at zero cost.